
Author: Mihai Avram | Date: 10/02/2021
The area of web scraping has really expanded in the last few years, and it helps to know some of the main frameworks, protocols, and etiquette so that you can build the next awesome Web Scraping tool to revolutionize our world! Or maybe just your local neighborhood, or workgroup – that’s fine too.
In this post, we will cover.
- What is web scraping?
- What are the main programming frameworks for web scraping?
- What are some of the main enterprise-level paid web scraping frameworks?
- A Python web scraping example where we extract some information from a site with Beautiful Soup
- A JavaScript (Node.js) example where we interact with Google Search using Puppeteer
- The Do’s and Don’ts of Web Scraping
Let’s begin!

What is web scraping?
With the web now hosting almost 5 billion web pages, it would be impossible to view each one of these pages personally. Even if you somehow knew the address of each page, and assuming that you are only looking at a page for about 3 seconds, it would take you nearly 500 years to view everything. Now imagine another scenario where you need to take different parts of the web, and organize them for a specific purpose. Perhaps a project to view car prices for your favorite electric car on many car dealership websites. To do this manually, again would take a very long time. This is where web scraping comes in, and is defined as such:
Web Scraping
The act of retrieving information from, or interacting with a site hosted on the web using an automated programming script or process. This process is also known as a web crawler or bot.
One can write such an automated script fairly easily, with less than 10 lines of code, and automatically retrieve information from the web, obviating the need to search, organize, or interact with the website manually. For some specific use-cases, like the car dealership example above, this can save a lot of time, and frankly, there are a lot of business models built by this advent of web scrapers. Some examples of working business models that use web scraping are tracker services that can alert you when something you desire is back in stock, review sites that aim to aggregate people’s opinions, travel websites that want to provide trip data in real-time, and even the much-contested media/marketing practice for gathering users’ profiles and preferences. There are even plausible examples of these web crawlers filling out website profiles for some people, submitting posts, and solving captchas – but this is yet another debated gray area where one must be careful to not get in legal trouble.
With just a little bit of coding knowledge, one can do some really interesting things to retrieve, organize, and even interact with various sites online. In theory, one can automate almost anything done manually on the web – with a wide range in difficulty level of course.
What are the main programming frameworks for web scraping?
Language Agnostic Tools
Playwright – One of the best language-agnostic and feature-rich tools for web scraping. Use it if you are scraping or testing complex applications, are building tooling in multiple languages, or need to perform end-to-end testing.
Selenium – An older and popular language-agnostic tool for web scraping that inspired many of the newer frameworks. Use it if you are working on large scraping or testing projects that need scale, are building tooling in multiple languages, and don’t mind spending a more time on configuration.
While Playwright and Selenium each have their own pros and cons, you can judge for yourself what is the best tool for your job via this comparison article.
Python Frameworks

Scrapy – An open-source scraping framework used to extract data from websites in any format which is built with efficiency and flexibility in mind. Use it for complex projects that require scraping multiple sites in various ways.
Beautiful Soup – A Python scraping library that one can use to parse a webpage easily and quickly. Beautiful Soup is a minimal version of Scrapy with only a fraction of the functionality; however, if parsing a web page is all you have to do – Beautiful Soup is the perfect tool for it. Use it for simple projects where all you need to do is scrape the elements of one web page.
MechanicalSoup – An interactive library that builds on top of Beautiful Soup and provides functionality to not only parse a web page, but also interact with it like filling forms, clicking drop-downs, submitting forms, and more. Use it if you need to interact with web pages.
Honorable mention – Pyppeteer (a Python version of Puppeteer)
JavaScript Frameworks

Cheerio – A fast and flexible JavaScript library inspired by jQuery that can parse elements of a webpage. Use it if you want to quickly extract elements of a web page.
Puppeteer – A NodeJS library that can both scrape a webpage, and also interact with any website by filling forms, clicking buttons, and navigating around the web. Use it for a full web automation experience.
Apify SDK – A web scraping platform that can quickly span and scale your web automation needs in a web browser. From retrieving web pages to parsing web pages, and even interacting with web pages, Apify can do it all and has custom code libraries and server infrastructure to quickly assist you. Use it if you need to start an involved scraping and web automation project that requires a lot of computing resources.
Java Frameworks

Jaunt – A complete web scraping framework from Java that can scrape and interact with web pages. Use it if you need to both parse web pages and interact with them.
jsoup – A simple web scraping solution that can parse web pages. Use it if you need to quickly parse web pages.
Ruby Frameworks

Kimurai – A scraping solution for Ruby that provides a one-stop shop to scrape and interact with web pages.
Honorable mention – Mechanize and Nokogiri Gems
PHP Frameworks

Goutte – A PHP framework made for web scraping that can both scrape and interact with web pages.
What are some of the main enterprise-level paid web scraping frameworks?
What if I want to scrape the web and I don’t know or don’t how to code? You ask with concerned vitriol. That’s where more of the paid services come in where you can start to use any types of services as hands-on as No Code to as hands-off as fully automated services. Below is a list of some of the most popular paid scraping services that can help you quickly get started without having to know how to code.

A custom API that easily scrapes any site and takes care of proxy rotation, captcha solving, and anti-bot checks. It works by entering the URL of any site you want to scrape, and Scraper API returns all the information. Besides the benefit of it being hands-free, it is also cost-effective by providing free requests and relatively cheap pricing rates. Use it if you want the simplest and cheapest solution to scrape sites in a rudimental way.

One of the most established players in the web automation space. Apify allows you to leverage their thousands of plugins that have been created by the Apify community which can solve most of the common scraping problems. From scraping Instagram to interacting with Travel websites – Apify can do it all. They even have custom solutions where their developers can write custom code to solve your need. The solution also works if you have coding chops and want to do everything yourself. You simply write the code and Apify can host and run the code as well as provide you with proxy rotation and security measures to make sure your scraping scripts do not get blocked. Apify is also comparatively cost-effective compared to the other custom scraping options out there. Use it if you want the most comprehensive options for web scraping at an affordable price.

A point-and-click approach to web-scraping. The way it works is by interacting with the Parsehub desktop app; opening a website there, clicking on the data that needs to be scraped, and simply downloading the results. Parsehub also allows for data extraction using regular expressions or webhooks. One can even host scraping pipelines that run on a schedule. Parsehub is a fairly expensive option. Use it if you want to scrape data using little to no coding chops.

This product takes a different approach by giving a user access to a trillion connected facts across the web. The user can extract them on demand with the service which may include Organizational data, Retail data, News, Discussions, Events, and more. The organization also provides Big Data and Machine Learning solutions that can help you make sense of the data collected, establish patterns, and build IP that solves problems with its data. Use it if you want access to a treasure trove of data that is tied to your project or organization – and are able to afford it.

Similar to Parsehub, this product includes a point-and-click solution to web scraping. It also offers all features of web scraping such as IP rotation, Regex tools to clean up data, and scraping pipelines that can run scraping projects at scale. While Octoparse can solve almost any scraping problem, the service is certainly not cheap. Use it if you want to scrape data using little to no coding chops.

A more custom solution to the Scraping API, ScrapingBee allows users to have more control over websites they scrape with little to no coding experience. They offer a bit pricier rates; however, they can write custom solutions to anybody willing to outsource the task to professionals. ScrapingBee also provides proxy rotation to bypass bot restriction software. Use it if you want a cost-effective way to simply scrape a website – with the option of having custom support from professional developers.
Also if you are a person that likes to live on the edge seat of innovation, here are some feature-rich up and coming contenders in this space:
- Browse AI (#5 Product Hunt product of the month – Sept. 2021)
- ScrapeOwl (#4 Product Hunt product of the day – Oct. 2020)
- Crawly (#2 Product Hunt product of the week – 2016)
Here are more resources if you wanted to learn more about different web scraping tools and offerings.
- 8 Best Web Scraping Tools (by Hevo)
- 12 Best Web Scraping Tools in 2021 to Extract Online Data (Popupsmart)
- 15 Best Web Scraping Tools for Data Extraction in 2021 (Guru99)
- The 14 Best Data Scraping Tools and Web Scraping Tools (ScraperAPI)
- The Best Web Scraping Tools for 2021 (ScrapingBee)
Now let’s get our hands dirty with some scraping projects shall we?
A Python web scraping example where we extract some information from a site with Beautiful Soup
Let’s start with a simple Python scraping example. For this, we will use the Web Scraping Sandbox where we can very quickly explain and elucidate the main ideas behind web scraping.
As a prerequisite, make sure to have Python 3 installed as well as Beautiful Soup. Once you have Python 3 simply run the following in a shell terminal to install the needed packages.
$ python -m pip install beautifulsoup4
and
$ python -m pip install requests
Now let us take a look at the code.
# Imports
import requests # Used to extract the raw HTML of a web page
# Used to read and interact with elements of a web page
from bs4 import BeautifulSoup
from typing import Dict, List # Optionally used for type hints
# Functions
def extract_web_page_contents(url: str) -> List[Dict[str, str]]:
"""
Requests HTML from the url, and extracts information from
it using Beautiful Soup. Namely, we are extracting just
a list of books on the page - their names and prices.
Args:
url (str): The url where we are web scraping.
Returns:
book_names_and_prices (List[Dict[str, str]]):
Names and prices of all books retrieved from the
web page.
"""
# Used to store book information
book_names_and_prices = []
book_information = {
'name': None,
'price': None
}
try:
# Extracting web page contents
web_page = requests.get(url)
web_page_contents = BeautifulSoup(web_page.content, 'html.parser')
# Extracting the names and prices of all books on the page
for book_content in web_page_contents.find_all(
'article', class_='product_pod'):
# Useful to visualize the structure of the HTML of the book content
print('book content: ', book_content)
# Extracting the name and price using CSS selectors
book_title = book_content.select_one('a > img')['alt']
book_price = book_content.select_one('.price_color').getText()
# Creating new instance of book information to store the info
new_book_information = book_information.copy()
new_book_information['name'] = book_title
new_book_information['price'] = book_price
# Aggregating many book names/prices
book_names_and_prices.append(new_book_information)
return book_names_and_prices
except Exception as e:
print('Something went wrong: ', e)
return None
# MAIN Code Start
if __name__ == '__main__':
url = 'http://books.toscrape.com/'
web_page_contents = extract_web_page_contents(url)
print('All extracted web page contents: ', web_page_contents)
Code Explained
Starting at the “MAIN Code Start” section we define the URL to be a link to the Web Scraping Sandbox that has a fictitious list of books. The goal of this code is to browse to the first page on that website and extract the first set books on that page. Namely, we want to extract their names and prices.
The “extract_web_page_contents” function achieves this by first retrieving the HTML using the requests library, and then parsing those contents with the library called Beautiful Soup. Everything is easy up until this point. You may wonder, however – now that we got the HTML of the page, which looks something like this (below) – how can we extract the contents for those books?
<pre class="wp-block-syntaxhighlighter-code"><!DOCTYPE html> <html lang="en-us" class="no-js"> <head> <title>All products | Books to Scrape - Sandbox</title> <meta http-equiv="content-type" content="text/html; charset=UTF-8"/> <meta name="created" content="24th Jun 2016 09:29"/> <meta name="description" content=""/> <meta name="viewport" content="width=device-width"/> <meta name="robots" content="NOARCHIVE,NOCACHE"/><!--[if lt IE 9]> <a href="//html5shim.googlecode.com/svn/trunk/html5.js">//html5shim.googlecode.com/svn/trunk/html5.js</a><![endif]--> <link rel="shortcut icon" href="static/oscar/favicon.ico"/> <link rel="stylesheet" type="text/css" href="static/oscar/css/styles.css"/> <link rel="stylesheet" href="static/oscar/js/bootstrap-datetimepicker/bootstrap-datetimepicker.css"/> <link rel="stylesheet" type="text/css" href="static/oscar/css/datetimepicker.css"/> </head> <body id="default" class="default"> <header class="header container-fluid"> <div class="page_inner"> <div class="row"> <div class="col-sm-8 h1"><a href="index.html">Books to Scrape</a><small> We love being scraped!</small></div></div></div></header> <div class="container-fluid page"> <div class="page_inner"> <ul class="breadcrumb"> <li> <a href="index.html">Home</a> </li><li class="active">All products</li></ul> <div class="row"> <aside class="sidebar col-sm-4 col-md-3"> <div id="promotions_left"> </div><div class="side_categories"> <ul class="nav nav-list"> <li> <a href="catalogue/category/books_1/index.html"> Books </a>
...
...
...
</script> </body></html></pre>
There are two fairly straightforward ways to do this. The first, and most popular way is by using your browser’s development tools to select and identify the elements on the page you want to extract information from. The second is using Beautiful Soup to pretty-print and explore the elements within the code. The second use case may be more advanced, so let’s just focus on the first. Here’s an example below using the browser web tools.

In the above example, I browsed to the website via Google Chrome, hit F12 to launch the web tools, then clicked the selector button (see image below) to then guide my mouse and click on the book I wanted to extract. The book called “The Light in the Attic”
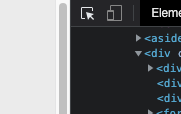
On the right side of the image above you will see that the exact HTML content that needs to be extracted automatically became highlighted. The trick is to notice that every single book is under the “article” HTML tag, and has a class of “product_pod”. Hence, I directed Beautiful Soup to retrieve all instances of articles with that given class, and voila – we now have a list of all the book contents. You may now be thinking to celebrate with a glass of sparkling 💦 , ☕ , or 🍺 if you are old enough; however, not so fast. While we have the book contents, we still have them in HTML format, and so, we must use more selectors to extract the exact content we want (name and price).
The price is the easiest of the two because if we explore the HTML of a given article, we will observe that the class for each price element is “price_color” – so we just create a Beautiful Soup selector to get the HTML element with that class, which contains the price within the text.
The book title is a bit more difficult to extract as we don’t quite have a class we can hook into. Class properties (e.g. class=”price_color”) and Ids (e.g. id=2343) are much easier to hook into because they have higher specificity – are typically more unique for our purposes. Whereas, let’s say we want to find all “a” elements on the page, well, there could be dozens if not hundreds of them! It does help to understand the basics of CSS selectors, and that can help you write rules to identify these elements faster. If you’re interested in learning the basics of CSS selectors, check out this guide. For the purposes of this example, however, if we find the element which includes the title by exploring the HTML via dev tools – we will observe that each title is included in the “alt” property of an element called “img” which is the child of another element called “a”. You could do this by hand by exploring the HTML structure in the dev tools. Or, if you want to take a shortcut, you can simply find any title, select it, then right-click on the HTML formatting of the selector, and click on the “Copy selector” directive (see image below for an example).

You can then paste it into your favorite text editor and you will see that it will yield a CSS pattern that is very close to the one you will use in the code. For instance, here is what the selector contents would be in the example case above:
#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a
This tells us roughly what we suspected, there is an “a” element that has a parent of “article”. Then all we have to do is extract the “alt” property as we do in the code, and we have just extracted the title!
Feel free to review the comments of the code for a deeper dive on how the scraping works with Python and Beautiful Soup. I tried to make the code example as self-explanatory as possible. Now that you feel more comfortable with this basic example – how about you challenge your understanding by looking to extract the book contents for 10 of the pages? Hint: You may need to use the aspect of pagination for this.
A JavaScript (Node.js) example where we interact with Google Search using Puppeteer
Let’s now delve into a more complex scraping example with JavaScript where we will interact with information on a web page using the Puppeteer API. In our simple example, we will simply go to Google, and run a quick google search.
As a prerequisite, you will have to install the latest version of Node.js and npm, and once you have both installed you can install puppeteer by running the following in a terminal:
$ npm install puppeteer
Now let us take a look at the code.
// Imports
const puppeteer = require('puppeteer'); // Used for interacting with a website
// Functions
/**
* Interacts with a website present at a certain url.
* For our use-case, this url is Google, and we are
* simply just searching something using the search bar.
*
* @param {string} url The url we are browsing to, and
* interacting with.
* @returns {void}
*/
const interactWithWebsite = async (url) => {
// Starting a browser session with puppeteer
const browser = await puppeteer.launch({ headless: false });
// Opening a new page
const page = await browser.newPage();
// Browsing to the url provided, and waits until page loads
await page.goto(url, { waitUntil: 'networkidle2' });
// Filling in the search as "Best guides for web scraping"
await page.$eval(
'input[title="Search"]',
(el) => el.value = 'Best guides for web scraping',
);
// Clicking on the Google Search button
await page.evaluate(() => {
document.querySelector('input[value="Google Search"]').click();
});
// Waiting for the results
await page.waitForSelector('#result-stats');
// Waiting for 5 seconds to admire the results
const waitSeconds = (seconds) => new Promise(
(resolve) => setTimeout(resolve, seconds * 1000),
);
await waitSeconds(5);
// You can do more stuff here, like retrieve the results like we did
// in the Python example above
// We are done, closing the browser
browser.close();
};
// MAIN code start
const url = 'https://google.com';
interactWithWebsite(url);
Code Explained
The code starts with the “interactWithWebsite” function which will browse to Google. We first launch a browser, open a new page, and go to the URL we searched, waiting for it to load. Then, we find the input field with an attribute of “title” called “Search” – and fill it with our query. Just as in the Python example above, one can use the browser web tools to find the component on the page, and the properties, as well as CSS selectors, needed to retrieve them with code. Below is an example of finding the search field component, and the HTML that it is defined by – from there we can create the CSS selector to hook into it.

Finally, we find the “Google Search” button which is an input field with a “value” attribute of “Google Search”, and click it. On the resulting page, there will be an element with the id of “#results-stats” – and we wait for it to load. Our magical and automatic google search is now complete! Feel free to review the comments of the code for a deeper dive on how the scraping works in Puppeteer and Node.js. I tried to make the code example as self-explanatory as possible.
Now that you have learned to both retrieve information from and interact with web pages, you should be well on your way to create some automation magic! When you do start – it will be important to understand some scraping etiquette which we will discuss next.
The Do’s and Don’ts of Web Scraping
While it may seem like web scraping is a free and easy way to extract information from the web, the web is no longer a wild west. This means we have to be careful how we interact with various sites, otherwise, we risk being a nuisance at the very least, and even possibly fined or punished for breaking the law in the worst case.
The most important theme to remember from this post if you don’t remember anything else is the notion of not doing any harm to a website, its users, and its owners.
Below are some specific Do’s and Don’ts to help you apply the theme above and engage in web scraping in an ethical way:
- Use only one IP connection
- Crawl at off-peak traffic times. If a news service has most of its users present between 9 am and 10 pm – then it might be good to crawl around 11 pm or in the wee hours of the morning.
- Follow the terms of service of a website you are crawling, and especially if you have to sign up or log in to use the services within.
- Some websites have a robots.txt file that lists the rules and limitations that scrapers should follow when scraping and interacting with the websites automatically.
- If you are crawling to present the content in a new way, or solve a problem – make sure that the solution is unique and not simply copy/pasting content. The latter can easily be seen as copyright infringement.
- Don’t breach GDPR or CCPA rules
Here are some articles to delve more into this topic:
- Best practices for web scraping (zyte)
- Is Web Scraping Legal? The Definitive Guide (CrawlNow)
- Web scraping is now legal (Tom Waterman)
- Web Scraping and Crawling Are Perfectly Legal, Right? (Benoit Bernard)
Additionally, here’s an article that describes the robots.txt file at length
Conclusion
That’s all for this post. I really hope that you have enough basic knowledge and guides to get you started in creating an ethical and world-changing web scraper!










