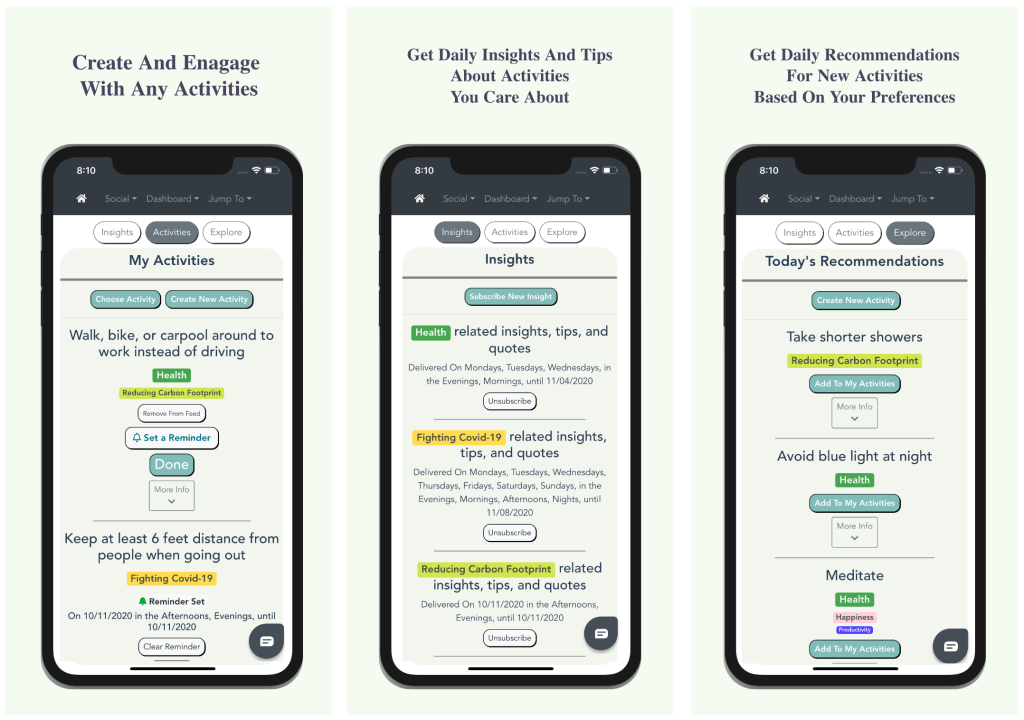
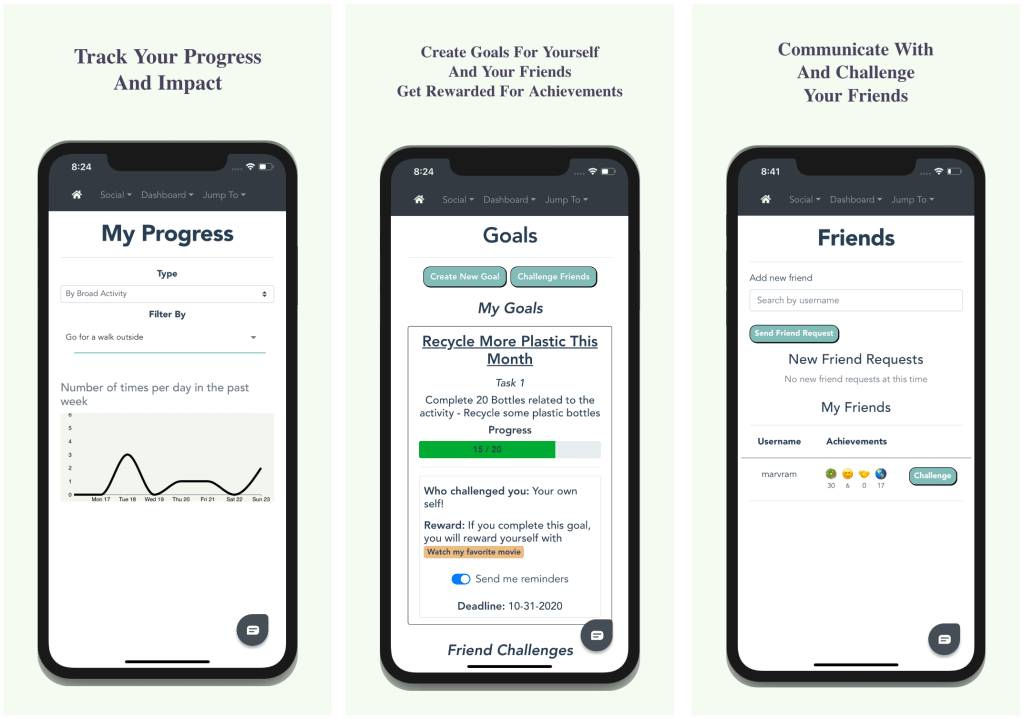
After reading various books, essays, and blog posts on what it takes to build a startup I’ve decided to create a step-by-step guide for it that is all-encompassing. Note that this content is heavily influenced by Lean Startup thinking and Running Lean by Ash Maurya, which in my opinion are the best books on succeeding with startup projects as a bootstrapper. A bootstrapper is someone who builds quickly themselves or with a small team and takes as little capital as they can in the early stages. I realize that there is some bias here as there are many other philosophies to building a startup in regards to investors, hard-tech, research projects, or geographical location. I believe that US-based tech founders who don’t mind being technical, and funding their startup without taking too much initial capital will deeply resonate with this guide. For everyone else, I’m sure there is something for you here as well, though one or two of the steps may not apply to you or be relevant.
Below is the list of steps that you can take to incrementally build a successful product. If you follow the guide closely and don’t skip any steps, you should have a high chance of success. Good luck!
1. Come up with a problem to solve

Do this by investing in your passions and living in the future. And no I don’t mean build a space laser and pretend like you’re a space-faring creature from StarTrek. Instead, push yourself to the boundary of your passion by using the best and newest tools, and know both the hackneyed and edgy facts about the topic.
Why focus on problems and not solutions? Most creators make the mistake of focusing first on the solution and fall into the trap of building something that nobody wants because it doesn’t solve their problems. Problem first, solution second.
Become an expert, and push the boundary. For instance, if you want to build a health app for your watch, buy all the health watches you can and try all the features to become a super user. Many problems will then reveal themselves to you, and very likely you will run into those problems yourself which is a great bonus!
Here are some great additional posts if you want to learn more about this topic:
- How To Get Startup Ideas – Paul Graham @ Y Combinator Partner
- How to Brainstorm Great Business Ideas – Courtland Allen @ Indie Hackers
- Organic Startup Ideas – Paul Graham @ Y Combinator Partner
- Crazy New Ideas – Paul Graham @ Y Combinator Partner
- Frighteningly Ambitious Startup Ideas – Paul Graham @ Y Combinator Partner
2. Do some market research to understand if and how this problem is being solved today

Okay, so you have an idea. What if the problem you are trying to solve is too difficult to solve with today’s technology. Or perhaps, what if there are dozens of popular solutions to your idea and it will be difficult to break in and serve a feasible audience? Or even more grim, while the problem is feasible and there is no competition, maybe the number of people who find this problem to be a big enough problem for them is small. These are all valid questions and one must do some market research to figure out the answers to these questions.
How can you do this?
First, start with your favorite search engine and do some searching to see if other products solve the problem you’re trying to solve, or even better, people and communities who care about the problem. Then, do some searching on ProductHunt for similar products that solve this problem, and try to read the reviews of these products wherever you can (e.g. Google Play for Android apps, Apple’s App Store, and review boards like ProductHunt). Try to understand what the customers care about, and what they say about this problem. This should give you extra insights on how to proceed.

Next, use your favorite market research tools like Google Trends, Thomasnet.com, statista, or Ubersuggest. Use these tools to understand how popular the domain and problem you are approaching is, how big is the community of people you can serve, how big is the demand for the solution, and who are some of your competitors that have captured a lot of the market already, if any. You can also use paid tools like Crunchbase or SEMrush but I would say paying for these services is a bit overkill at this point. Right now, you should really understand the market, and once you are getting close to product-market fit (at a later stage) you can start paying for these services. If you remember nothing from this post, remember that a startup has very limited resources, and in order to optimize for efficiency, one must take the right action at the right time!
This part of our process is really just a gut-check. Only stop working on your idea and move on to something else if the market is too oversaturated (too many competitors), it seems like nobody cares about the problem, or the problem is too difficult to build with the current state of technology. Most of the time your idea will be okay and you can move on; however, if you are seeing negative signals like these, they will tell you that the journey might be difficult, so maybe you can pick another problem worth solving that will not have so much going against you and you can work with the wind instead of against the wind. This is however; at the end of the day your choice to make! If you are incredibly passionate about something, nothing can stop you, but you have to be ready to put in the work.
Here are some great posts if you want to learn more about this topic:
- Conducting Market Research – Entrepreneur
- 6 of The Best Market Research Tools for 2021 – Attest
- Top 18 Competitive Intelligence Tools for Advanced Market Research – SEMrush
- Market research and competitive analysis – SBA
3. Create and fill-out a few Lean Canvases from Leanstack (or any place you choose from – just google it) to brainstorm a few business models
The Lean Canvas is a quick business plan that only takes up one page which has been created by Ash Maurya. He very deftly explains the Lean Canvas and methodology behind it in his Running Lean book which I also highly recommend. Find a Lean Canvas from the Leanstack site or any site that you prefer. You can either fill the canvas out on your computer or print it out and write on it manually. I prefer the offline manual process as it allows me to sit with myself and think without being distracted by any screens. Below you will see the Lean Canvas along with the recommended order you should ideally fill it out in.
Lean Canvas Order of Execution Starting at 1 and Finishing at 9

Make at least one Lean Canvas to start, and try to make a few of them if you can as the process will help push you to brainstorm different ideas, variations, and canvases for your project. Finally, take your time with this process and be prepared to iterate and change this canvas in the future. This canvas is your business plan so be prepared to change it many times until you find the right mold to fit your project and business which actually works!
Loop

From this point on we are going to keep looping and pivoting around these following steps until we get to Product-Market fit. Don’t feel discouraged if you have to execute and re-execute the steps of this plan many times, this is part of the process! In startups and entrepreneurship, failing is your best friend. Failing is learning so that next time you can nail the process!
4. Create more Lean Canvas business plans if needed
5. Pick the best Lean Canvas to go with which can maximize learning and success
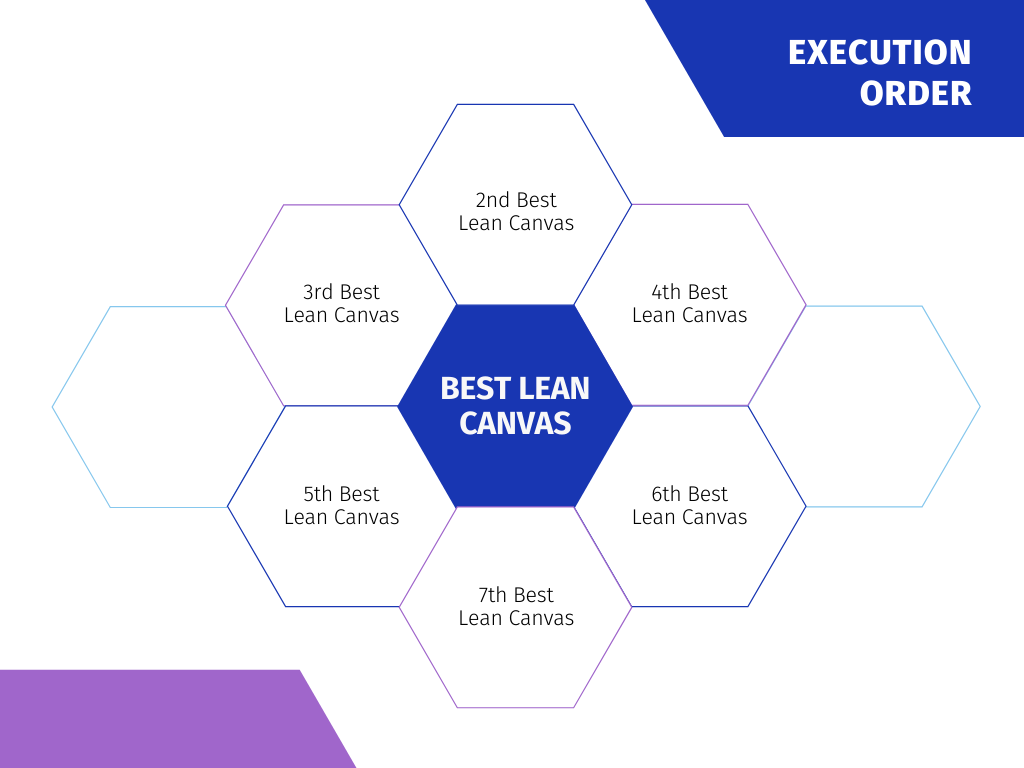
Identify the riskiest parts of your lean canvas, starting with risks in the recommended execution order (e.g. Problem, Solution, Customers, etc.) and execute the following steps with the notion in mind of maximizing learning. Create specific hypotheses around these risks such as (100 people will subscribe to my newsletter in one month if I publish it using the save-to-Pocket feature). Or if you are building a product specifically for parents, a hypothesis could be (10 parents will identify not having enough time to read articles about fitness because they don’t have time to search for new articles). As you validate these hypotheses around your biggest risks, and the customer segments and markets reveal themselves to you, keep reframing and re-iterating your Lean Canvas business plan.
6. Identify a few potential early adopters and talk to them

Don’t skimp on this step as it is one of the most important in the process. One of the biggest reasons startups fail is because they don’t understand their customers, so take time to get to know them and what their pain points are. You’re in this for the long term!
Find some people who fit the criteria of an early adopter and you can find them in one of your channels in your Lean Canvas. First, it helps to start with close friends or family as you get comfortable with the process. Meet with them for about 20 to 30 minutes and remember that meeting in person is better than meeting via video chat which is better than meeting via phone call which is better than asking the questions via e-mail/text. This is because you will get more signal in higher fidelity face-to-face meetings and will know more about the customer from either the novel points they bring up on their own, or their nonverbal communication cues. Keep the conversation casual, ask some variation of the following questions, and take lots of notes!
- What is the hardest part about doing X? (where X is the thing that you’re trying to solve)
- Tell me about the last time that you encountered this problem.
- Why was this hard?
- What, if anything, have you done to try to solve this problem?
- What don’t you love about the solutions that you’ve already tried?
- Ask any other questions that you may have in order to validate your main risks and hypotheses identified from above.
Conduct a handful of these interviews, stopping when you feel like you are not learning much of anything new from anybody you talk to. For some people, this is 4 interviews, for some 10 or even 30!
Here are some more resources to help you with this:
- How To Talk To Users (YC School) – Y Combinator
- The Mom Test by Rob Fitzpatrick (summary) – Cameron Nuckols
7. Create a very low fidelity solution to solve the problem – ideally in days/weeks instead of months/years

Based on your idea and feedback you received from talking to users, start creating your MVP! The MVP should not be perfect, but essential and functional. Identify the users’ major pain point(s) where the ideal number of features you should build is one. Don’t bloat the product with extra features or bells and whistles. When it comes to actually creating the product, constantly ask yourself what you can do to just solve the user’s problem in the simplest way possible without having to build too much. Some even go to extremes of building concierge MVPs where they fake the solution behind the scenes and they manually make things work. An example of this is manually looking for potential matches for someone based on their dating preference profile then sending them an e-mail with any finds. Regardless of how the MVP is done, whether manual or prototypal the whole point of the MVP is not to create a product that customers and investors would fall in love with (that’s a bonus). Instead, the most important part of the MVP is to get something out there so that you can get more feedback for users to see if your solution solves their problem, and if you should continue on this path, tweak the solution, or pivot to another solution.
Finally, try to push yourself to finish the MVP in a few days or a few weeks. This way you will eliminate a lot of unnecessary features, and beckon your brain to be resourceful and come up with novel shortcuts to quickly get to solutions in helping your users. Think bold here, and think quick – but still functional.
Here are some more resources to help you with this:
- How to Plan an MVP (YC School Video) – Y Combinator
- A Step-by-Step Guide to Build a Minimum Viable Product (MVP) – Net Solutions
- Relentlessly Resourceful – Paul Graham @ Y Combinator
8. Monetize your project right away if applicable

Whether or not you can get rewarded for your creation and people are willing to pay is one of the most important factors that can make or break your project and business. It is not sustainable to create and upkeep a project for free. And you will see that if you have not properly monetized it and it is constantly growing, it will become more and more difficult to upkeep as time and money are scorched from you while you keep the project going. This will increase the chances that you and the project will fail. Therefore, it is incredibly important to come up with and test pricing models early on so that you can learn who is willing to pay for the product, and under what strategy (e.g. sponsorships, subscription model, freemium, ads, etc.).
Here are some ideas that you can try:
- Talk to users and ask them for payment up-front to use the MVP. If they agree and want to pay, this is a really strong signal that you are building something valuable that they are willing to pay for. If this works, build towards a subscription model.
- Start a crowdfunding campaign around your project.
- Develop a freemium model where you have base features that are useful and draw the user in. Do this with the goal of getting the user to pay for the extra features because they are must-haves.
- Sponsorships or Patronage where organizations or individuals can support you for your work with various strings attached.
- Advertising.
- Fundraise from angel investors, and VCs (the best time to go to them is after getting to Product Market fit, and if you are okay giving away some control of the business)
Here are some more resources to help you with this:
- Startup Pricing 101 – Y Combinator
- How to Monetize a Freemium Business – Y Combinator
- Monetizing Podcasts and Newsletters – Y Combinator
9. Launch first, then again and again
Launch your low fidelity solution and measure people’s interest in it. After finishing your MVP, launch it as soon as possible. Don’t worry so much about making a bang, instead just try to get a few invested people to help you learn what they think of it and how it can be improved. Here are some ideas for where you can launch:
- Hacker News – https://news.ycombinator.com/yli.html
- Product Hunt – https://blog.producthunt.com/how-to-launch-on-product-hunt-7c1843e06399
- Reddit – https://medium.com/mobile-growth/nailing-your-product-launch-on-reddit-bdded3d25da9
- Beta List – https://medium.com/@FastFedora/how-to-get-into-trending-on-betalist-c58f07a768b7
- Kickstarter – https://www.easyship.com/blog/how-to-create-successful-kickstarter-campaign
- Indie Hackers – https://www.indiehackers.com/group/product-launch
- Any groups/communities (physical or virtual) that you are part of
After you launch on any of these platforms it is also very important to stay engaged with the audience. If they are commenting on your post, engage with them and continue the conversation to create buzz.
Remember, that the most important thing here is not to acquire thousands of users, but to acquire a few early adopters that can help you get to product-market fit.
For more information on this topic check out the following resource:
- Relaunch like a pro: 100+ places to launch, relaunch, and list your product – James Fleischmann @ Indie Hackers
10. Talk to users about your solution using Solution Interviews

Gather supportive users who are ideally your target demographic of early adopters and talk to them for about 30 minutes. The purpose of these interviews is for you to test your creation and really understand what your users think of it, thus learning how to improve it.
Here’s the general sequence of how this interview should go:
- Quickly introduce yourself and the purpose of the interview.
- Collect demographics about the user that can better enable you to pinpoint your early adopters and the customer profile they resemble (e.g. age demographic, gender, and other behavioral factors related to your solution).
- Tell them about the inception story behind your product.
- Show and explain how your product solves the few major problems they have ideally with a demo.
- Ask the users the following questions and note their feedback:
a) Which part of this demo or product did they resonate with the most?
b) What feature of the product could they live without?
c) Are there any features that the user thinks are missing from the current product? - Test out pricing with the user by anchoring on a starting price point for the product and gauging their reaction, and response.
- Ask the user if they can connect you with someone they know who they think could also benefit from your product so that you can talk to them next.
For more information on this topic check out the following resource:
11. Come up with and measure a few metrics that can enable you to measure success

Now that we launched a product and started the user acquisition/user feedback process it is time to measure our progress. This is a crucial step that will allow us to gauge how good we are doing and how close we are to product-market fit. When it comes to metrics, the #1 metric that matters should measure user retention. What does that mean?
It helps to lay out the user cycle as a funnel in which potential prospects use your product. Perhaps the user follows a pattern like this:
- User finds out about your product
- User goes to your landing page
- User signs up for your product (Acquisition)
- User logs in and does a few key activities (Activation)
- User keeps logging in to do various key activities (Retention)
The key activities from above will again require some learning on your part. You need to find out, for your product, which features and usage maps will lead a user to keep using your product? Perhaps they are first signing up and customizing their avatar in the app you built, or perhaps adding a friend in your app will help them stay activated. For a user to keep coming back, maybe they will have to open your app every couple of days, message a friend, and mark one of their goals complete. This journey widely varies from product to product, and it is important to find out what journey or set of repetitive actions will retain a user.
To find the secret to retention, you must first measure every single user you onboard every step of the way down the funnel we described above. The data you capture on them should be transparent as to when they looked at your landing page, when they signed up, and what activities they do every day. Once you hone in on users that keep using the app or product, try to see which activities they keep doing and that might be a good lead to tell you that these are activities and journeys to help with retention. Then, try to measure those metrics and journeys even more granularly if you can and zoom in on those metrics for every user. You can do this manually, using tools like Google Analytics, or even writing code to record user actions in your database.
Another helpful trick is dividing the measurement in user cohorts which we will discuss later.
Here are some more resources to help you with this:
- How to Measure Your Product (SUS 2018) – Y Combinator
- Measuring Retention For Startup – Neil Patel
- 10 Key Startup Metrics to Track Growth – Hirebook
- Growth for Startups – Y Combinator
12. Keep spreading the word, talking to users to get feedback, and measuring success
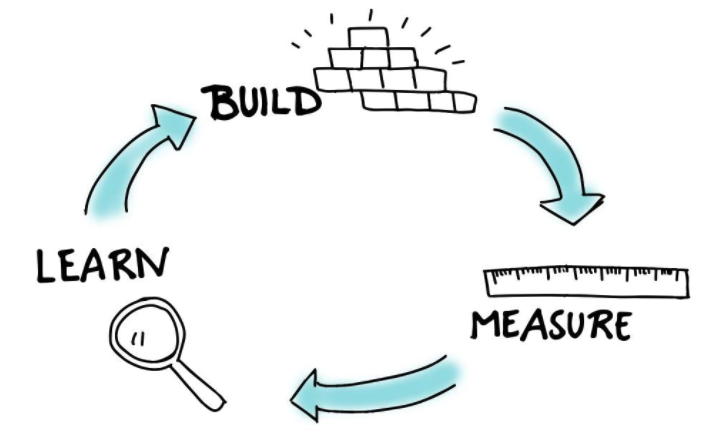
Get in the groove of recording every interaction you have, from acquiring users, talking to them, having them sign up, and the rest of the actions they take. Invest 80% of your time into a strategy that works and another 20% of your time exploring other avenues to acquire users (e.g. do a new launch, try a new user channel, or reach out on LinkedIn if you haven’t). Keep experimenting until you find the right niches, audiences, and channels for your users. Finally, keep talking to users using Solution interviews from above, and the new MVP interview we will discuss below. Focus these interviews on learning more from users, identifying your best target early adopters, and getting people to start paying you in advance for your product. Another important distinction point is that it is important to bring both new users and old users whom you have done Solution interviews with for the MVP interview.
The MVP interview:
Here’s the general sequence of how this interview should go:
- Quickly introduce yourself and the purpose of the interview.
- Collect demographics about the user that can better enable you to pinpoint your early adopters and the customer profile they resemble (e.g. age demographic, gender, and other behavioral factors related to your solution). If the user has already been through a solution interview, you may skip this.
- Show the user the landing page of your product and ask the users the following questions:
a) Is it clear what the product is about?
b) What would you do next? - Show the pricing page and ask the users what they think of the pricing model.
- Ask the user to sign up for your product as you watch them go through your product and ideally go through the activation flow.
- Record all the answers from above, then ask the final closing questions:
a) What did you think of the process?
b) Is there anything we could improve on?
c) Do you know what you can do next with the product?
d) Can we check in with you in a few weeks after you played around with the product some more?
Record all the information, and keep interviewing users with Solution and MVP interviews until you feel that you are no longer learning anything new.
- If success metrics keep growing, continue improving the solution based on user feedback. The goal here is to get to product-market fit.
What is product-market fit?
The holy grail of startups. It is the first step of building a viable business and a signal that you have built something which has strong market demand you can capture. A good way to measure that you are on the cusp of getting to product-market fit is that you retain 40% of activated users month over month. As highlighted in the step above, it is incredibly crucial that you come up with a way to measure activated users, and retained users – what that means for you and your product specifically, and be able to measure it for new monthly cohorts. This means that a user who signed up 3 months ago will no longer be part of this formula. You will always have sliding windows of one month of all users which you activated, and retained in January, February, March, … etc. and this will result in activation and retention percentages for these months. Here’s a quick example:
January:
Total users who tried your product this month: 100
Users activated this month: 20
Users retained this month: 5
% of retained activated users: 5/20 or 25%
February:
Total users who tried your product this month: 105
Users activated this month: 30
Users retained this month: 10
% of retained activated users: 10/30 or 33%
As you can see, we are getting close to the 40% mark. If you see 40% retention month over month it means that you are on to something and are ready for the Sean Ellis test. Which tests the percentage of users that would be very disappointed if your product went away.
The test is simply sending a survey to all of your users, and you can find the method here – Sean Ellis Test
If 40% of your surveyed users say that they would be very disappointed if they could no longer use your product, you have reached Product-Market fit!
13. If success metrics stay stagnant for many weeks, adjust your Lean Canvas based on user feedback, and start again from the beginning of the Loop (Step 4). Don’t be afraid to remove or recycle what you have built.
14. Continue this Loop until you get to Product-Market Fit – You got this!

Keep revising your lean canvas and going through the list above from step 4 above over and over again until you see metrics that grow consistently. This may take you one time to do if you are a veteran or you get lucky, and likely will take you a few times to do if you are diligent. If you have gone through this loop many times and are either a) exhausted from going through the loop with nothing to show for it, b) are finding signals that the problem is not worth solving – by all means, move on to something else unless you are infatuated with the idea. Being infatuated is not a bad thing as long as you’re okay with the long road ahead and the excruciatingly hard work it takes to get there. If you need some inspiration on this front you can read about any space programs like the Apollo or SpaceX – the amount of grit, will and persistence they have to succeed is superhuman.
So I hit Product Market Fit, now what!?
- Celebrate, this is a momentous milestone
- If you have not monetized your project yet, now is a time to do so
- Switch your approach to scaling and optimization
Stay tuned for the next post which will discuss scaling!
I plan on turning this into an interactive checklist for people to use as they plan and work on a project.
Leave a note in the comments or e-mail me at mihai.v.avram@gmail.com if you’re interested in something like this!
Happy building ❤